
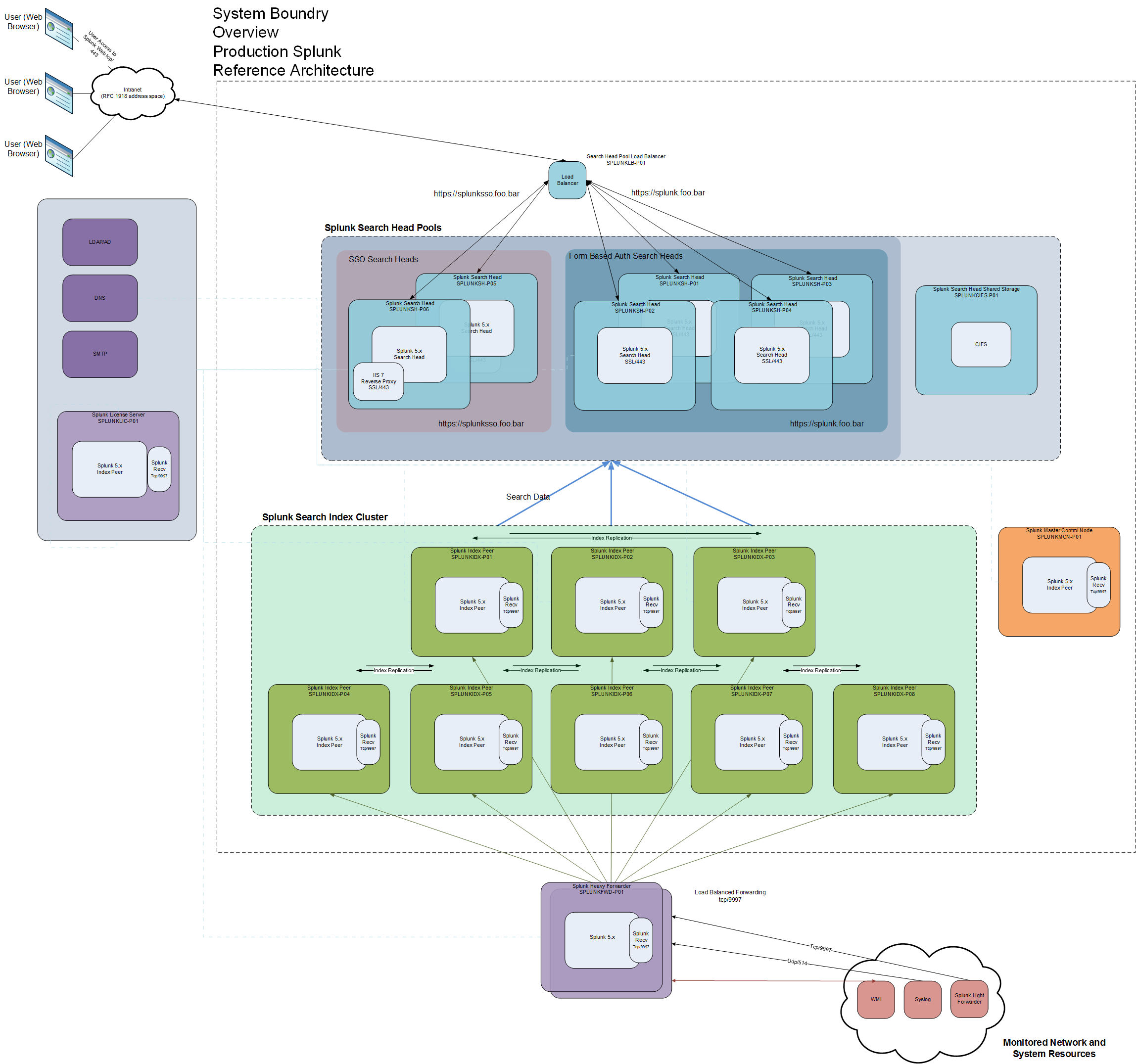
I’ve been pretty pretty excited about the latest release of Splunk and wanted to share my envisioned production Splunk cluster. The architecture is based upon Splunk’s own reference architecture and incorporates horizontal scaling via both search head pooling and search index clustering. Hooray for highly parallel, high performance, high availability data mining of unstructured data.
Spread the word